





HTML代码如何查询: 学习如何有效查询和理解HTML代码

在数字化的时代,了解如何查询HTML代码是非常重要的。HTML(超文本标记语言)是构建网页的基础,通过学习查询HTML代码,可以帮助开发者和设计师更好地理解网页结构,从而进行优化和调整。本文将详细探讨如何查询HTML代码,包括使用浏览器工具、网络爬虫技术、以及常用的代码编辑器。
一、使用浏览器开发者工具进行查询
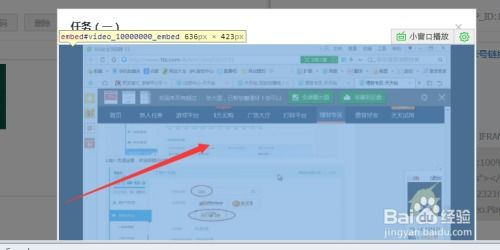
现代浏览器内置的开发者工具非常强大,能够帮助用户轻松查询和调试HTML代码。要打开开发者工具,用户可以右键单击网页的任意位置,选择“检查”或“检视元素”。这样可以查看所选元素的HTML结构和相应的CSS样式。
在开发者工具中,用户能够查看网页的DOM(文档对象模型)树状结构。DOM表示网页的结构化内容,通过展开和收起节点,用户可以深入了解元素的层次关系。同时,用户还可以修改HTML代码,通过实时更新查看变动效果,便于迅速测试和调试。
开发者工具还提供了一个“控制台”选项,可以用来执行JavaScript代码。用户能够使用JavaScript查询和操作网页中的HTML元素,这非常适合于前端开发人员进行调试和测试。
二、使用网络爬虫技术查询网页HTML
对于需要批量查询多网页HTML内容的应用场景,使用网络爬虫技术将是一个非常有效的选择。网络爬虫是一种自动访问互联网并提取信息的程序。用户可以使用Python的库(如BeautifulSoup或Scrapy)来编写爬虫程序,以便获取需要的HTML数据。
用户需要安装一个爬虫框架,Scrapy。通过创建一个爬虫项目,用户可以定义目标网页、提取规则和数据存储方式。一旦设置完成,运行爬虫程序后,它便会自动访问网页、抓取HTML代码,并按照事先定义的规则提取出用户所需的信息。
网络爬虫技术尤其适用于数据分析工作,收集多个竞争对手的产品信息、价格趋势,或者获取特定主题的文章内容等。这种方式不仅可以节省时间,而且可以从大量数据中提取有价值的信息。
三、利用代码编辑器查询本地HTML文件
除了在线查询网页HTML外,开发者通常需要在本地环境中工作。因此,学会使用代码编辑器(如Visual Studio Code、Sublime Text等)查询和编辑HTML文件非常重要。代码编辑器提供了友好的界面和丰富的功能,支持语法高亮、代码补全和格式化等多种功能,使得用户在编写时更加高效。
使用代码编辑器,用户可以快速打开本地的HTML文件并查看其代码。许多编辑器还支持搜索功能,用户可以通过特定关键词在代码中进行快速查找。用户也可以利用版本控制工具(如Git)管理代码的变化,确保开发过程的高效性和稳定性。
代码编辑器的另一大优势是其扩展性,用户可以根据自己的需求安装各种插件,增加新的功能。这使得编辑和查询HTML代码的过程更加灵活和高效。
四、与建议
学习如何查询HTML代码是现代网页开发的基本技能。通过使用浏览器开发者工具、网络爬虫技术以及代码编辑器,开发者可以在不同的环境中灵活操作HTML代码,提升工作效率。
对于初学者,建议从浏览器开发者工具入手,逐步熟悉HTML结构和网页的基本组成。随着经验的积累,用户可以尝试使用网络爬虫技术开展更多的数据提取工作。掌握使用代码编辑器将使得本地开发更加高效。
无论是一个网页的简单修改,还是大数据分析,了解和查询HTML代码都是不可或缺的。而随着互联网的不断发展,HTML代码的应用场景也会不断扩展。希望本文对学习如何查询HTML代码提供了有用的参考与指导。
