





redis 数据库 锁:深入理解 Redis 的锁机制

redis 数据库 锁:深入理解 Redis 的锁机制
什么是 Redis 数据库锁
在现代软件开发中,尤其是在微服务架构中,分布式系统的出现让数据共享和一致性变得愈发复杂。Redis 数据库作为一种高效的内存数据存储工具,提供了简单而有效的锁机制,确保多线程或多进程环境中的数据安全与一致性。
Redis 锁的必要性
数据锁是一种用于控制对资源的访问的技术。它可以防止多个进程或线程同时修改同一资源,从而避免出现数据不一致的情况。在 Redis 中,锁的使用场景广泛,包括缓存更新、分布式任务调度、以及共享资源的同步访问等。
,在一个用户管理系统中,如果多个请求同时尝试添加用户,将会存在潜在的重复数据问题。使用 Redis 锁能够在同一时刻只允许一个进程执行添加操作,从而有效避免上述问题。
Redis 实现锁的方式
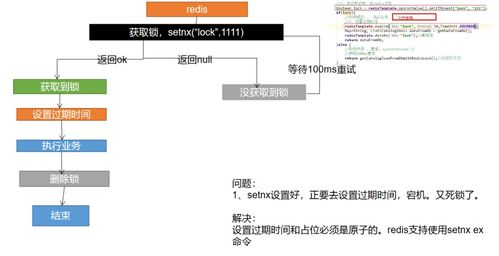
在 Redis 中,我们可以通过使用简单的 SETNX 命令(“Set if Not eXists”)来实现分布式锁。该命令会在键不存在时为其赋值,而当该键已存在时则返回 0,这使得我们可以实现简单的锁定逻辑。
以下是一个简单的 Redis 锁的示例:
SETNX lock_key unique_id
在这个场景中,`lock_key` 是我们的锁的键,`unique_id` 是一个唯一标识符。只有当 `lock_key` 不存在时,SETNX 命令会成功执行。
但要注意,仅通过 SETNX 命令并不能解决锁超时的问题。为了防止死锁,我们还需要设置一个过期时间,这可以通过 SET 命令结合 EX 参数实现:
SET lock_key unique_id EX 10 NX
此命令会将 `lock_key` 锁定并设置 10 秒的过期时间。若在 10 秒内操作未完成,锁将自动释放。
分布式锁的进一步实现
虽然上述方式实现了基本的锁机制,但在分布式环境下还需要考虑许多问题,网络延迟、进程宕机等情况。在这种情况下,可以采用 RedLock 算法来实现更安全的分布式锁。
RedLock 算法主要借助多个独立的 Redis 实例来实现锁,通过以下步骤确保锁的可靠性:
- 获取当前时间。
- 在所有 Redis 实例上尝试获取锁,设置过期时间。
- 如果锁的数量达到大多数实例,表示成功获取锁,继续处理。
- 处理完任务后释放锁。
- 如果获取锁失败,则在计算的超时时间内多次尝试,直到成功或者无法获得锁。
这种方式能更好地处理分布式环节中的各种问题,确保系统的稳定性和一致性。
Redis 锁的应用场景
Redis 锁在许多场景中显示出其必要性,比如下列场景:
- 并发任务处理:当有多个线程同时处理某个任务时,通过 Redis 锁可确保任务的唯一性,从而避免并发造成的数据丢失或重复处理。
- 缓存在不一致情况下的更新:在缓存中更新数据时,使用 Redis 锁可避免因多个请求同时更新而导致的缓存不一致。
- 分布式服务中的数据一致性:在微服务架构中,一个服务操作涉及到另一个服务时,应使用锁机制确保数据的一致性。
Redis 锁的注意事项
在使用 Redis 锁时,有几个注意事项需要保证锁的有效性和安全性:
- 锁的超时处理:务必为锁设置合理的过期时间,以避免死锁的情况发生。
- 处理异常情况:在操作期间,如果发生异常,要确保在适当的情况下释放锁,防止造成资源的浪费。
- 唯一标识符:使用一个明确且唯一的标识符,确保能正确释放相关的锁。避免其他线程或进程错误释放锁。
Redis 数据库锁机制是现代分布式系统中不可或缺的一部分,能够有效管理并发操作中数据的一致性与完整性。结合适当的锁算法,如 RedLock,可进一步提高系统的稳定性,确保数据的安全。在实际开发中,合理利用 Redis 锁能够帮助开发者构建更加高效和可靠的应用程序。
用户在使用 Redis 锁时,牢记锁的生命周期、释放策略和并发控制,将会在复杂的系统中保留数据的稳定性和一致性。
